 image.png
image.png
最近有两条线在同时跑着。
一条是 AI Agent。高强度用 Codex 玩了很多东西——搭工作流、调项目、管笔记,越玩越觉得,当 AI 能直接读写本地文件的时候,很多事情的性质就变了。

另一条是 Markdown。去年 Obsidian 还是个小众软件,到了今年这会儿,感觉快变成 AI 时代人手必备的 app 了。越来越多人开始用 Markdown 写笔记——不是因为它多酷,而是它恰好是 AI 最擅长处理的格式:纯文本、结构化、不锁数据。
这两条线本来各跑各的,直到它们撞在一起:本地 Markdown + 本地 AI Agent,简直是绝配。
前两篇算是铺垫。第一篇聊了 Markdown 是什么——跟 AI 协作的时候用 Markdown 写提示词,脑子更清醒,输出更干净,复制粘贴到飞书排版直接白送。第二篇聊了为什么 Markdown 在 AI 时代复兴了:大模型的训练数据里全是 .md 文件,它对 AI 来说不是需要「解析」的格式,而是母语;本地 .md 文件让 AI 能直接碰到你的数据——不走 API、不配认证、零摩擦。
说实话,云端的笔记工具,飞书文档因为工作协同没办法还在用,其他的我几乎全卸载了。本地 Markdown + 本地 AI Agent 实在是太好用了。
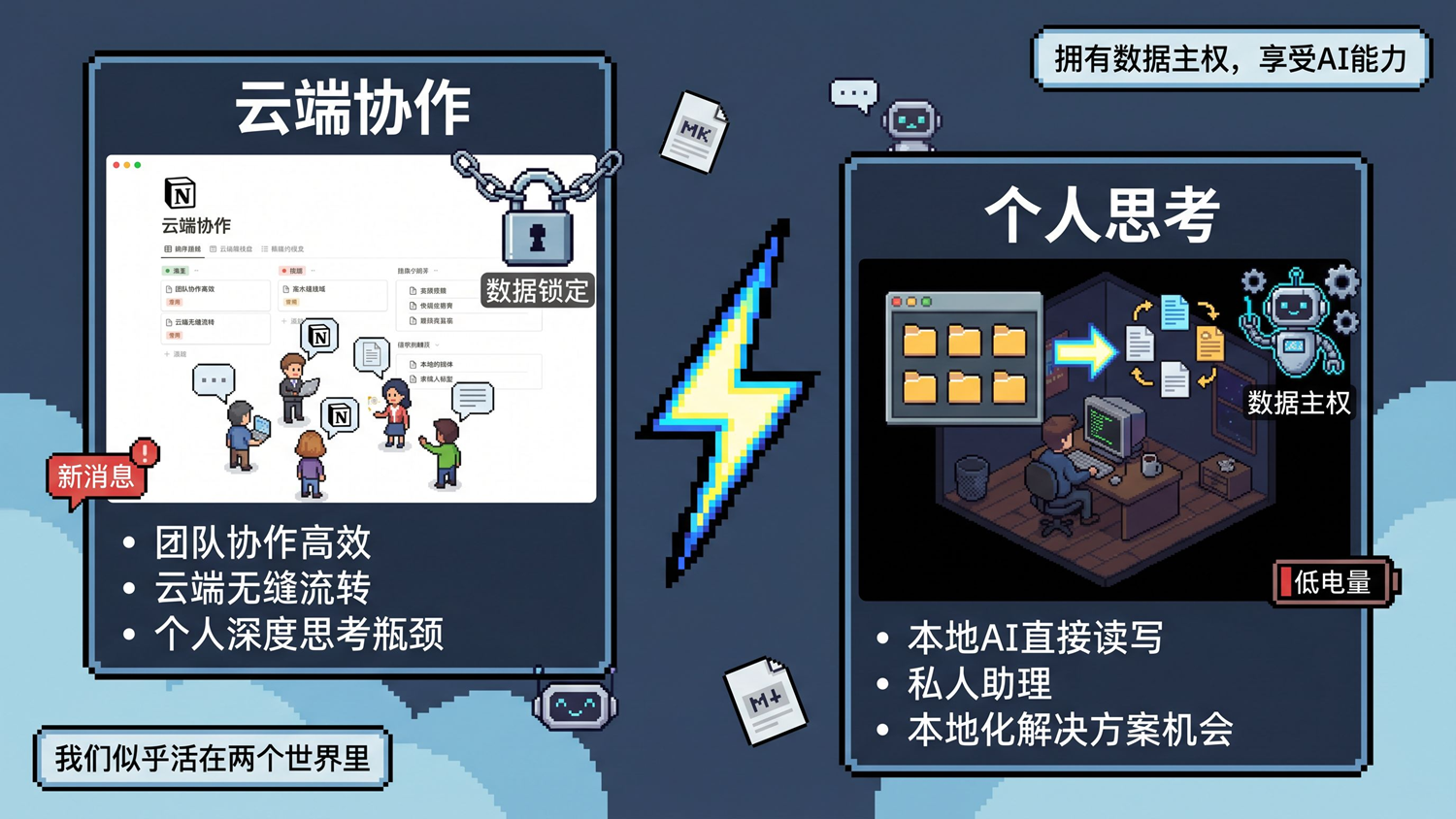 image.png
image.png
今天直接分享一下过去一个月我搭的一套知识系统。本来只是想给自己的笔记本升升级,结果在 Codex 的帮助下,亲眼看着它从一个「笔记整理工具」慢慢变成了一个 nb 的东西。
有朋友看完前两篇真去建文件夹了。一个哥们微信问我:「笔记记好了,这么放着,和云端比有啥不一样嘎?」
要是你没让 AI 进来,那确实没区别——只是换了个存储介质。该找不到的还是找不到,该忘的还是会忘。
但如果你让 AI 进来了,并深刻参与到你的工作+生活+记忆,你会发现一切变得有意思起来了。
 image.png
image.png
不论短期对你有没有用,但是那种让一个 AI 成长得越来越像你,是不是很好玩的?
在开始之前,你需要准备两样东西:
AI Agent:我只推荐 Claude Code 或 Codex——如果你在 2026 年 5 月读到这篇文章,我建议直接搞一个 GPT Plus。ChatGPT 内置的 Codex 体验已经足够好,不需要额外折腾命令行,开箱即用。
Markdown 阅读器:Obsidian——这是我们整个知识库的「家」,所有 Markdown 文件都住在这里。免费、本地、纯 Markdown,不锁数据。
一些替代品:AI Agent 可以用 Cursor、Antigravity、Trae、Qoder 等等,Markdown 阅读器可以用 VS Code、Zed 等等。
从 Karpathy 的三个文件夹开始
Andrej Karpathy——OpenAI 前研究总监、特斯拉自动驾驶前负责人——今年 4 月开源了一套叫“LLM Wiki”的个人知识管理方案。核心思路一句话就能讲清楚:人负责投喂原始素材,AI 负责把素材“编译”成结构化的知识库。
非常非常推荐直接去品一品原文:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
直接发给你的 AI,然后深度去聊一聊结合自己的场景如何使用。
他怎么做的?三个文件夹加一个规则文件。
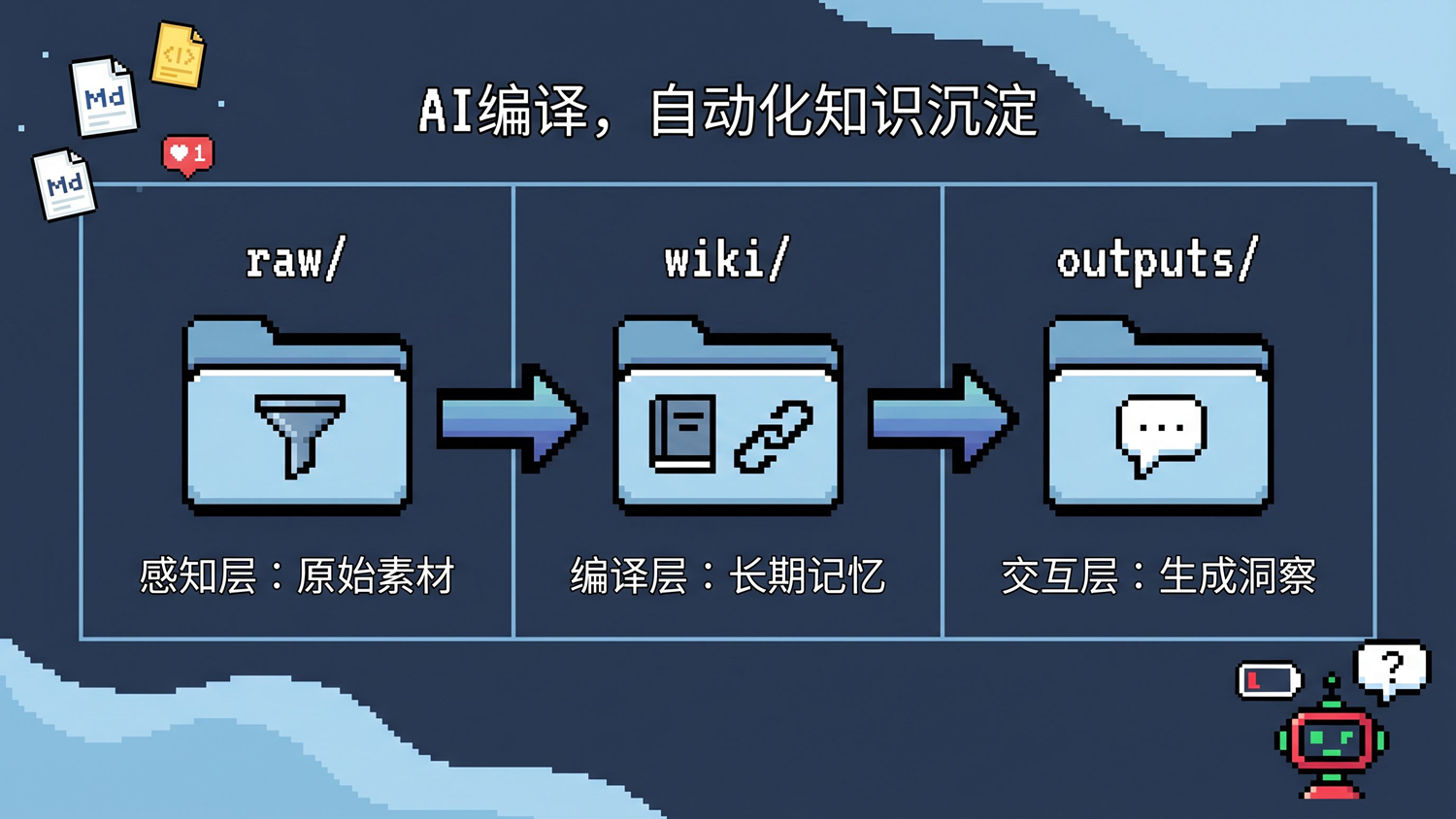 image.png
image.png
raw/** 是入口。** 往里扔什么都行——文章、论文、代码仓库、数据、图片。他用 Obsidian 的 Web Clipper 插件把网页直接裁成 .md 存进来。这个文件夹的规则是零:不判断、不分类、不整理,只管扔。
wiki/** 是核心。** 这个目录里的内容人基本不碰,全是 AI 写的——做摘要、分类、提取概念、写成文章、建立互相之间的链接。你往 raw/ 里扔食材,AI 在 wiki/ 里给你做成菜。你不需要自己整理,AI 帮你维护一个有组织、有关联的知识体系。
outputs/** 是对话归档。** 存你跟 AI 的问答记录。有意思的是,这些问答经常会被“归档”回 wiki/,变成新的知识节点——你的每一次提问都在反哺知识库。
还有一个 CLAUDE.md,在 Codex 中也可以叫 Agents.md,相当于给 AI 的上岗培训手册:这个知识库长什么样、文件怎么组织、你有什么偏好,都写里面。
他的知识库已经积累到大约 100 篇文章、40 万字。他说本来以为需要上 RAG(检索增强生成),但发现 AI 自己维护索引和摘要就够了。
最让我印象深刻的是他说的“linting”——定期让 AI 对整个知识库做“健康检查”:找不一致的数据、补充缺失的信息、发现有意思的关联、建议新的研究方向。AI 不只是帮你存东西,它在帮你维护和进化这个知识体系。
但 Karpathy 的方案偏“研究型”——他在深挖某个技术领域,素材是论文和代码仓库。我想,大部分人的日常不需要那么硬核。
同样的,这个只是一个框架,完全可以结合自己的情况,让 AI 帮我去定制化一个符合自己需求的框架,比如说 wiki 一层不够,我可能要分为 project 和 topic,可能还有子项目等等。
我简化了一下。大家可以复制我的结构,直接留言我会发给你。或者参考我的想法和结构,让 agent 帮你定制化。
我的版本:一个 Inbox 搞定一切 draft
核心就一个理念:先扔,后整理,整理的活交给 AI。
第一步:零摩擦记下来
我在 Obsidian 里建了一个 inbox/ 目录。什么都往里扔——学了个新概念,打开 Obsidian,噼里啪啦写几行扔进去。不想标题,不想分类,不想格式。哪怕只有一句话,哪怕错别字满天飞。
如果你配置好了 OpenClaw、Hermes 等 agent,或者一些小龙虾类的办公 agent,直接让他帮你连上本地的 obsidian 文件夹的 inbox,只要保证你说的话,用一个触发词(比如说“记录一下”),就可以将对话内容保存到 inbox 目录中,进阶一点你也可以建1个 skill,升级为发任何文章链接也能记录。
读了篇好文章,摘几段关键内容扔进去。跟同事聊完一个方案有了新想法,掏出手机记两句。甚至是 TODO、购物清单、突然冒出来的一个念头——都往里扔。
为什么要这样?因为绝大多数人的知识管理死在入口。让一个人打开笔记软件、新建文件、想标题、选文件夹、打标签——五步下来,那个灵感早就跑了。或者你觉得这个想法“还不够成熟,等想清楚了再记”,然后就再也没记。
Inbox 的意义就是把入口的摩擦降到零。不判断,不分类,不整理,只管记下来。
当你发现你可以发语音给微信的 bot,飞书的机器人,都可以记录的时候,打开电脑的 obsidian 来记录已经是最落后的记录方式了。或许当你熟悉了这个记录的流程后,说不定每天记录日记就很好玩了。
第二步:让 AI 替你整理
inbox 里攒了一批乱七八糟的笔记之后,我让 AI 来做格式化处理。具体做四件事:
**第一,格式化,但不删信息。**AI 会把你的碎片文字整理成可读的 Markdown——加标题、理段落、修语法——但不会丢掉你写的任何内容。很多人怕 AI 整理会把自己的东西“改没了”,不会的。你可以明确告诉它:只做格式化,不删除、不改写任何实质内容。
第二,加 metadata. 在每个文件顶部加上创建时间、来源、主题分类这些元信息。手动加会烦死,AI 加起来毫无负担。
第三,半自动打 tag。 为什么是“半自动”?AI 读完内容会建议 3-5 个标签,但最终你扫一眼确认。因为标签体系要跟你自己的思维方式匹配——AI 可能会打一个“认知科学”的标签,但你自己习惯叫它“思维模型”。这个校准过程很快,做几次之后 AI 就会学会你的偏好。
第四,建双向链接。 AI 读完你的新笔记,会扫一遍你已有的笔记库,把相关内容用 [[]] 链接起来。你自己做这件事需要记住“我之前写过什么”,AI 只需要全文检索——它比你记性好。
给你看个真实的 before/after。
扔进 inbox 的原始内容是这样的:
第一,完全没背景就想一个人靠 AI 搞定前后端、数仓加亿级数据分析,这不现实。你连 HTTPS、脚手架、API 是啥都不知道,AI 接不到准话就会开始胡糊弄,到头来 Token 白烧,系统全是漏洞根本没法上线。如果必须单干,听我一句劝,先用 Vibe Coding 搞点单机或简单逻辑的小东西碰碰运气,想做复杂系统老老实实去拉个有五年经验的硬核工程师。
第二,选用合适的工具。同时必须分清模型和工具的边界,Claude Code 或者 Cursor 只是干活的 Agent 工具,它们能力上限取决于大模型。总有人抱怨工具生成的页面太丑、不好用,其实是自己审美和指导能力不行,AI 生成的 UI 效果好不好,核心全看你自己的 Vibe 设计和审美上限在哪里,别总自己不行还怪工具不给力。
第三,记录的重要性,记住“记录即创作”,把实操踩坑的过程写下来,很多没想明白的逻辑在写的过程中自然就通了。记住所有的和ai的对话记录,只要你认真看了,都值得记录,这都算是你学习到的东西。
第四,多停下来沉淀下,ai做好了一个app,回过头问问ai是怎么用的,有什么best practice学习到了,以及下次做类似的,或者把这个做成其他类型的(ios app、或者小程序等等)要做什么
第五,有空学习一下部署的知识,当vibe coding出来后,如何真是落地分发,在公网上让更多的人体验到,可以慢慢接触一下服务器的知识了,具体怎么学问ai就行。
AI 处理完变成了:
---
title: 最近用 AI 写代码的一些碎碎念
date: 2026-05-20
tags: [AI编程, 踩坑, vibe-coding]
---
最近用 AI 写代码攒了几条经验,随手记一下。
## 别一个人硬刚复杂系统
没背景就想靠 AI 搞定前后端 + 数仓 + 亿级数据分析,不现实。HTTPS、脚手架、API 是啥都不知道的话,AI 接不到准话就开始胡糊弄,最后 Token 白烧,系统全是洞。
非要单干的话,先用 Vibe Coding 搞点单机小东西碰碰运气。想做复杂系统,老老实实拉个五年经验的硬核工程师。
## 工具的上限是你自己
Claude Code、Cursor 只是干活的 Agent,能力天花板是背后的大模型。有人老抱怨工具生成的页面丑——其实是你自己审美和指导能力不行。AI 出什么 UI,核心看你 Vibe 设计和审美的上限在哪。别自己不行怪工具。
## 记录即创作,踩坑写下来
实操踩坑的过程写下来,很多没想明白的逻辑写着写着就通了。所有跟 AI 的对话记录,只要认真看了,都值得记——这都算是你学到的东西。
## 做完了回头问一句
AI 搞完一个 App,别直接关了。回头问它:这东西怎么用的?有什么 Best Practice?下次做类似的,或者移植成 iOS App、小程序,要改什么?
## 部署这事,迟早得学
Vibe Coding 把开发门槛打下来了,但东西怎么让别人用上?公网落地分发这块,慢慢接触服务器知识吧。怎么学?问 AI。
## 相关笔记
- 和 AI 协作的一些原则(之前记过几条,跟这个有点关系)
当然,它不是完美的——有些我习惯的说法被它改了,标签也不一定每次都准。但以前我自己整理这么一条,取标题、想分类、回忆有没有相关笔记,少说十分钟。现在看一眼,改改标签,一分钟搞定。剩下的九分钟,我拿来记下一条。
这个让 AI 整理的过程,你慢慢的需要知道你想要什么样子的,需要什么结构的,当你确认了后,完全可以把它变成一个 agent skill,然后每一次直接调用 skill 就可以整理了。
第三步:定期 Review
inbox 攒了十几二十条的时候,我会让 AI 做一次 Review,做三件事:
生成“知识周报”。 扫一遍最近新增的笔记,生成一份摘要。这东西本身就有价值——你能看清自己过去一两周在关注什么、思考什么。有时候看到周报我才发现,原来我这段时间一直在想同一个问题,只是在不同的场景下以不同的面目出现。
找潜在关联。 这是 AI 最擅长的事。你三周前记的一条读书心得,和昨天写的一条工作复盘,可能藏着某种你自己都没注意到的联系。你不会翻到,因为它们躺在两个不同的文件里。但 AI 会翻。
有一次 AI 告诉我:我三个月前记过一条笔记研究 OpenClaw 的自动记忆刷新机制——对话快被压缩的时候,AI 自己判断“这段对话里有什么值得记住的”然后写进文件。而两周前我在日记里随手写了句“忙了一周回头看,真正重要的事就三件,剩下全是噪音”。AI 说这是同一件事——不管对 AI 还是对人,记忆的核心不是存了多少,而是知道什么该留。
我自己根本没意识到我写了这两条,更不可能把它们联系起来。
**还有一些时候,**有些东西你当时只记了一句话,但 AI 发现你在不同时间、不同场景下反复提到类似的想法——它会说:“这个主题你已经攒了不少素材,要不要我帮你整理成一篇完整的文章?”
到这一步,这套系统已经不只是“帮我存笔记”了。它在帮我看清自己在想什么。
然后事情开始变了
这是我写这篇文章真正想说的部分。
Inbox 工作流跑了几周以后,我发现一件事:我往里扔的东西变了。
一开始是“知识”——学了一个新概念、读了一篇好文章、看到一个有意思的数据。但慢慢我开始往里扔别的东西。
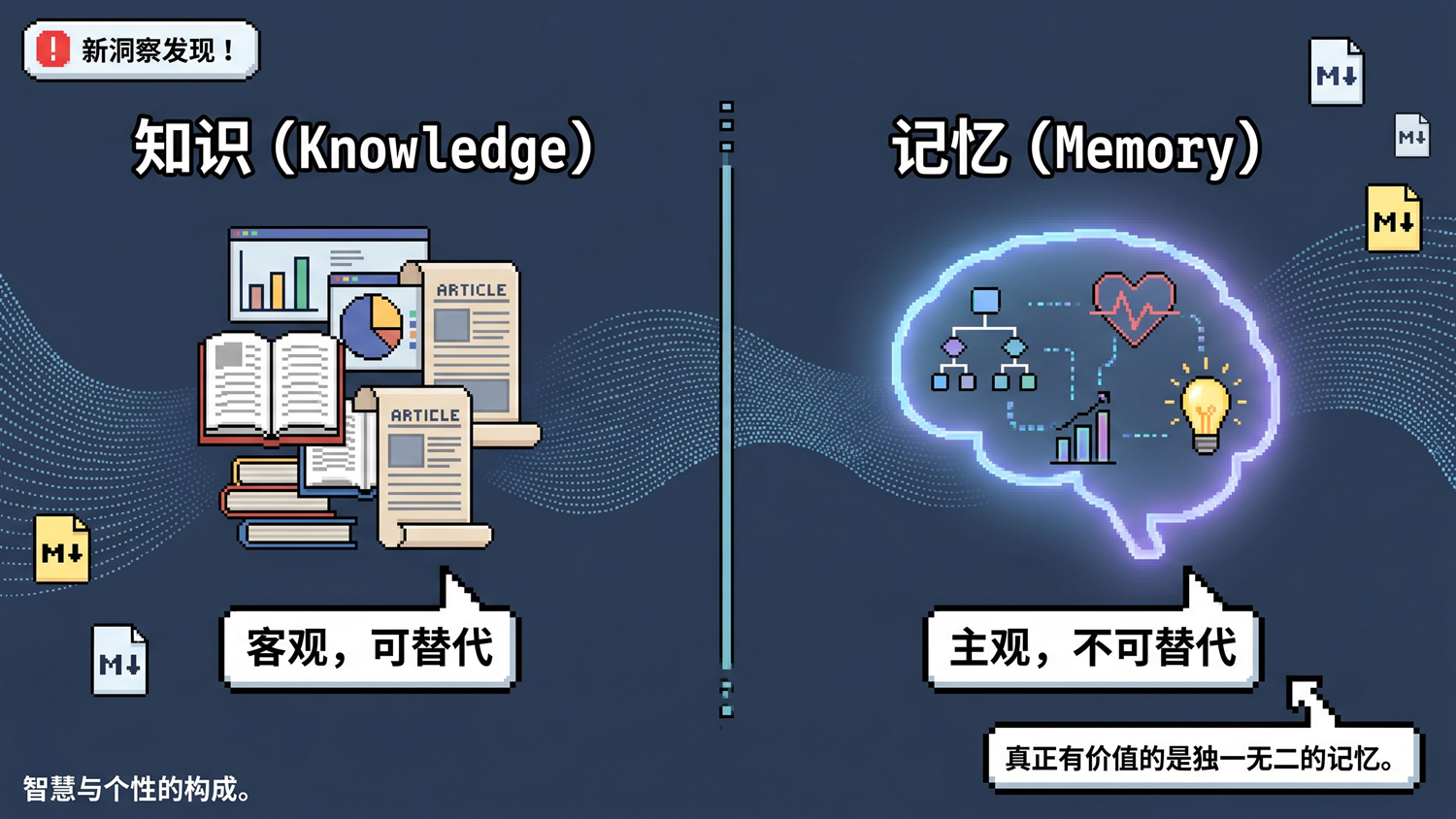 image.png
image.png
我扔进去一条决策记录——为什么在 A 方案和 B 方案之间选了 B,当时考虑了哪些因素。不是因为我觉得这是“知识”,而是因为我隐约觉得半年后我可能会忘了自己为什么做了这个决定。
我扔进去一条人际关系笔记——和一个朋友聊完天,记了几句他最近关心什么、聊到了什么。不是刻意为之,就是顺手。
我扔进去一条情绪日志——那天特别焦虑,随手写了几行“为什么焦虑、触发了什么、怎么缓解的”。
我甚至扔进去一条未成熟的想法——一个产品 idea,完全不知道能不能做,只有一个模糊的方向,连标题都想不出来,就写了三行字扔进 inbox。
我一开始以为我搭的是一个“知识库”。但现在回头一看,我在往里扔的东西,已经远远超出了“知识”的范围。
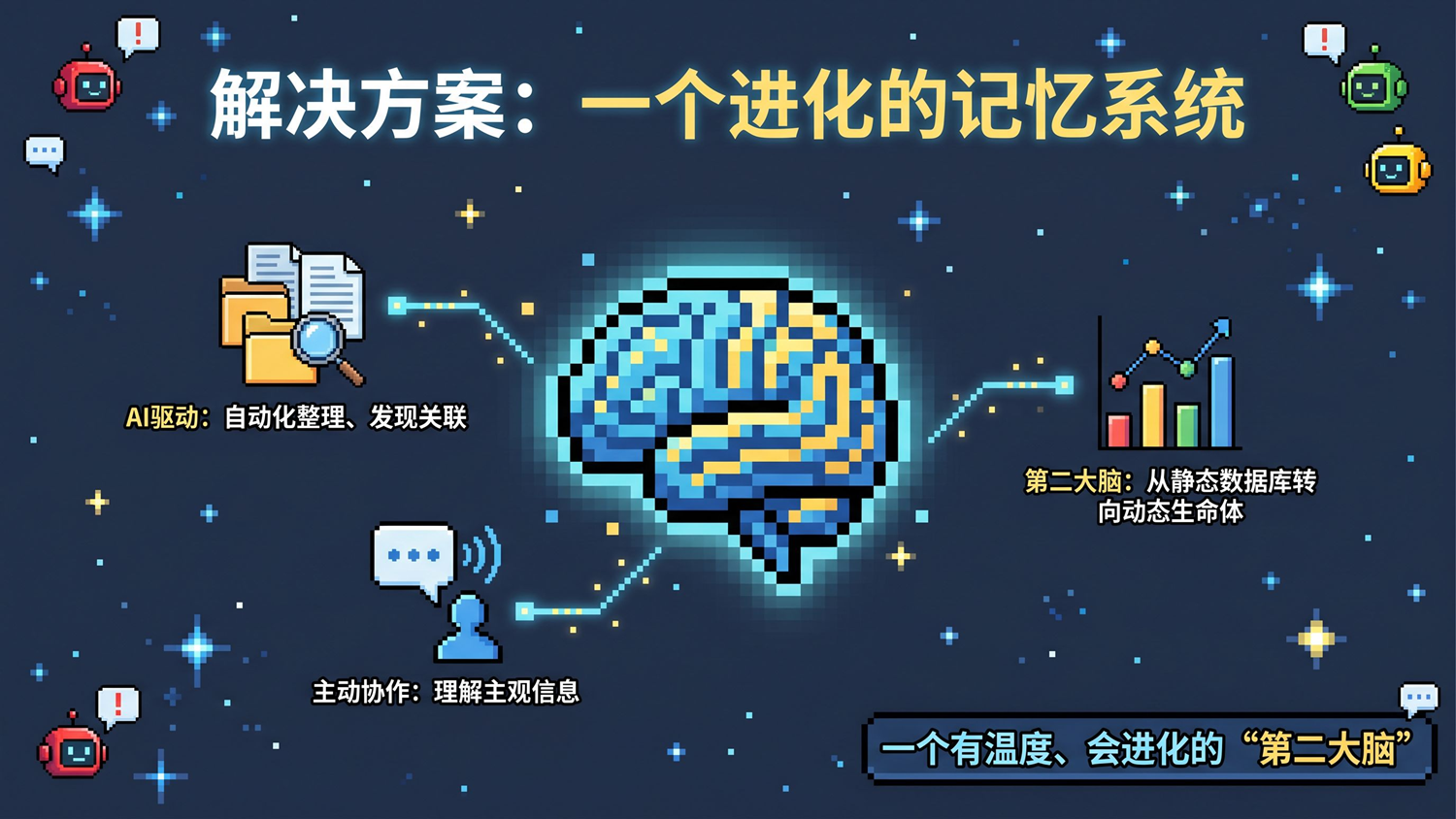 image.png
image.png
知识库和记忆系统,本质上是两件不同的事。
知识库存的是“客观事实”——文章摘要、学习笔记、技术文档。这些东西可以被更好的内容替代。你今天读了一篇更好的文章,完全可以覆盖去年那篇。
但记忆系统存的是“主观世界”——你的想法、感受、关系、决策、情绪。这些东西不可替代,因为它们是独一无二的。2026 年 4 月你为什么选了 B 方案?这不会被任何文章替代。你的焦虑触发点是什么?这不会被任何数据覆盖。
知识库是图书馆,记忆系统是日记本 + 大脑 + 人生档案。
我当时的文件夹已经从最开始的 inbox/ + notes/,慢慢长成了这样:
my-brain/
├── inbox/ # 零摩擦入口
├── knowledge/ # 知识:学习笔记、文章摘要、技术文档
├── memory/ # 记忆:经历、重要对话、人生节点
├── opinion/ # 观点:对话题的立场,随时间演化的轨迹
├── ideas/ # 想法:灵感、点子、未成熟的思考
├── relationships/ # 人际关系:重要的人、关键对话
├── decisions/ # 决策记录:为什么选A不选B
├── journal/ # 日志:情绪、反思、心理状态
└── BRAIN.md # 规则文件
每个文件夹里,就是一堆 .md 文件。没有什么神奇的技术,就是纯文本。
AI 自己也是这么管理记忆的
如果只是我一个人这么搞,你可能会觉得这是个人偏执。但我后来发现,两个最前沿的 AI Agent 框架——OpenClaw 和 Hermes——用的也是 Markdown 文件管理记忆。
OpenClaw 的原则直白到粗暴:“文件就是真相来源,模型只记住写入磁盘的内容。”记忆就是一个 MEMORY.md 加几个按主题分的 .md 文件,对话快被压缩时 AI 自己判断什么值得留、什么该扔。Hermes 更进一步,MEMORY.md 存事实,USER.md 存用户画像——每次对话 AI 都能“看到”你是谁。
这就是“记忆”和“笔记”的本质区别。笔记记录事实,记忆理解含义。
它们为什么都用 Markdown?四个条件同时满足:人能读、AI 能处理、可版本控制、可搜索。它是人机共享记忆的最佳载体。
如果 AI Agent 可以用这套系统管理自己的记忆,你为什么不能用同样的方式管理你的?
但有一件事我得诚实地说
这套系统很好用,但它不便宜。
4 月份我疯狂用 Codex 管理这个知识库。一开始 1-3 个 Plus 账号,我觉得挺够的。但随着记忆文件越来越多——几百个 .md 文件,几千条记忆——每次交互的 token 消耗开始暴涨。算了一下账,确实肉疼。
你让 AI 做一次 Review,它要扫几十个文件,每个文件都是 token。你让它找关联,它要交叉比对不同文件夹里的内容。你让它做健康检查,那更是一场 token 盛宴。
这跟写代码不一样。写代码是“一次性”的——你让 AI 帮你写个功能,写完了就完了。但记忆管理是持续性的——你每天都在用,每天都在往里加东西,每天早上 AI 都在“回忆”昨天的你。
现在我在摸索几个降低成本的方法:
分层记忆。 不是所有记忆都同等重要。热记忆(最近两周的)每次都在上下文里,温记忆(最近三个月的)偶尔调用,冷记忆(半年以上的)归档后只在需要时才检索。类似 OpenClaw 的向量索引——先查索引,命中再读原文。
主动遗忘。 不是所有东西都值得永久保留。定期 Review 的时候,有些记忆其实已经不重要了。让 AI 帮你判断:这条记忆在过去三个月被引用过吗?没有的话可以考虑归档甚至删除。
等技术进步。 Context window 在变大,token 成本在下降。这个问题会随时间缓解。今天的“不便宜”,明天可能就是“可以接受”。国产的 Coding Plan 效果也不错,我个人推荐 Kimi 家的;DeepSeek-V4 的高缓存命中模式(DS4-Pro)也肯定能满足你的需求。
我说这些不是要吓退你。恰恰相反——诚实地说清楚成本,你才能真正评估这件事值不值得。对我来说,它是值得的。你花钱买健身房会员、买书、买课程,这些都是对自己的投资。让 AI 帮你管理记忆,本质上是一回事。
感兴趣的话,留言告诉我你的目录结构长什么样,或者聊聊你是怎么让 AI 帮你管笔记的。交流交流。
都看到这里了,不如打开电脑去试试
如果你看到这里手有点痒了,今天就做三件事:
装 Obsidian. 免费,全平台支持,纯本地存储。如果你已经在用其他 Markdown 编辑器,也完全可以。核心是本地 .md 文件,不是特定软件。
建文件夹 + 规则文件。 至少建一个 inbox/ 和一个 knowledge/。自己写一份规则文件存到根目录,改名叫 CLAUDE.md 或 .cursorrules。
装一个 Codex 或 Claude Code,然后再编辑器中开整,IDE 随你用 vs code 或者 cursor,又或者 trae 都可以。
然后就开始往 inbox 里扔东西。学了什么、想到什么、看到什么、做了什么决定、跟谁聊了什么——不管三七二十一先记下来。
攒个十来条,对 AI 说一句“帮我整理一下 inbox”。
第一次看到 AI 把你的碎碎念变成结构化记忆的时候,你就明白了。
最近写了好几个 blog,其实在说同一件事。
前两篇说 Markdown 是 AI 的母语、本地 .md 是 AI 时代的最优解。这篇说的是:把这些东西搭起来之后,它会变成什么——从一个帮你整理笔记的工具,慢慢变成一个越来越懂你的系统。
以前知识管理的核心是“整理”——你得花大量时间分类、打标签、建结构。现在核心变成了“投喂”和“对话”——你只管把东西扔进去,AI 帮你整理、帮你关联、帮你发现。
但还有一个问题我没聊:这些记忆存好了,怎么呈现?怎么分享给别人?怎么让它不只是“你一个人的系统”?
下一篇聊聊 Markdown 和 HTML 的关系——Markdown 是记忆,HTML 是皮肤。你的第二大脑,需要两层架构。
这个系列还没完。